

从零入门LL分析法
编译原理2019-09-06 02:12:37特点: LL文法是一种自顶向下、自左向右分析的方法, 本文章主要讲如何通过手写一个分析器来学习编译原理中的相关知识点;
老规矩,从四则运算下手:
待计算的表达式如下:
1+2+3+4*5+6*7+8
如何手写一个分析器来处理?
处理该表达式的重点在于处理+ - / *优先级,同样对于一门编程语言来讲重点也是能否准确处理好各种优先级(当然不限于+/*-这四种运算,还涵盖了语言中的每个语法的优先级)。
以上述四则运算为例, 其中用到了 +(加法)和 * (乘法),(减法和除法与加法和乘法优先级相同,为了方便观看,只拿加法和乘法为例)
乘法的计算优先级要高于加法, 也就是 3+4*5 的时候,要先计算4*5 再计算3 + ?, 而对于1+2+3的运算来说 ,则是优先级平等按照自左向右的顺序处理就可以了,下面来通过文法简单归纳一下:
PS:文法是用来描述语法结构规范的定义,例如:中文语法=主语+谓语+宾语
文法构造
分析过程
设有文法ADD为加法, MUL为乘法,NUM为数字,结合数学上的运算优先级顺序,则有下列描述:
ADD = (ADD | MUL | NUM) + (MUL | NUM)解释:加法表达式的结构是 (
加法表达式
或者
乘法表达式
或者
数字
)
+ 加号 + (
乘法表达式
或者
数字
)
对于加号左侧,优先尝试解析加法,然后乘法,然后才是数字。
例如 1*2 + 3 * 4 + 5,
按照解析顺序,注意是解析步骤,不同于运算顺序, 解析顺序是从优先级最低的开始,第一步,先尝试寻找加法运算,然后乘法,则上式步骤为:
A + B + 5。
A=1*2, B=3*4.
MUL = (MUL|NUM) * NUM解释: 乘法表达式的结构是 (乘法表达式 或者 数字) + 乘号 + 数字.
NUM = 0~9解释: 数字的结构是由0~9组成的字符串
文法总览
ADD = (ADD | MUL | NUM) + (MUL | NUM)
MUL = (MUL|NUM) * NUM
NUM = 0~9
上述三个结构已经很清晰的描述优先级,按照自左向右的推导顺序。
加法表达式的推导顺序 ,先看加号的左侧推导方法:
1.加法表达式 + (乘法表达式 或者 数字)
2.乘法表达式 + (乘法表达式 或者 数字)
3.数字 + (乘法表达式 或者 数字)
按照123的顺序,1失败则跳到2, 2失败则跳到3,3失败就表示整个分析流程失败了(加号右边的表达式同理处理)。
也就是说在加法的处理中,加号左侧的结构优先级是 加法 > 乘法 > 数字:
如:
1 + 2 + 3 ,正确处理顺序是: (1+2)+ 3 而不是 1 + (2 + 3)
注意:虽然 在数学常数的运算中(1+2)+ 3 和 1 + (2 + 3)的结果相同,但在程序语言中两者先后不同则会导致结果不同,如 a.f() + a.f1() + a.f2() ,f 和f1及f2 三个方法内部互相影响,调用函数的顺序不同,则会影响其他函数的返回值。
1 + 2 * 3 的正确处理顺序是: 1+ (2 * 3), 而不是 (1+2) * 3。
构造范式
现在看起来已经很清晰了, 一般情况下,按照该文法编写三个方法 :ADD() ,MUL() , NUM()就可以进行分析了,但是在这里需要注意另外一个问题, 左递归问题。
如上述MUL文法结构 : MUL = (MUL|NUM) * NUM
逻辑描述没有问题,但是在实际操作中MUL会陷入无限的自我调用的死循环中,例如
// 抽象代码
void mul(){
mul();//<- 死循环
....
}
为了解决这个问题,需要消除左递归,以上面乘法表达式为例,我们进一步写出他的范式。
首先对文法做等价变换:
MUL = (MUL|NUM) * NUM => MUL = (MUL * NUM) | (NUM * NUM)
对于该表达式,已知部分是NUM * NUM ,在不考虑递归的情况下,已知部分就是
MUL = (NUM * NUM)
在这里再次使用尝试使用已知部分对递归部分做等价变换,
把递归部分提取出来为MUL':
MUL' =(MUL * NUM)|(NUM * NUM)
则已知:
MUL = MUL' | (NUM * NUM)注意:灰色部分为后面项的递归,
则得到:
MUL' = (MUL' * NUM)
代入替换:
MUL' = ((MUL' * NUM) * NUM)
进一步替换, 则最终变成了
MUL' =(((((....NUM * NUM....) * NUM) * NUM) * NUM) * NUM)
为NUM(*NUM)[1~∞], 则用正规式表达则为 MUL=NUM(*NUM) +, 注意:最后面的蓝色加号表示:加号前面的项出现1~多次,至少1次,加号 前面的项为括号中的内容。
结论,直接左递归文法是该文法非递归部分的无限循环。
顺带说下间接左递归, 它是由多个文法推导出的左递归,例如:
A = BC
B = DE
D = A | F对A做推导变换:
B代入: A = DEC
D代入: A = (A|F) EC
推导结果出现了A的左递归.
解决思路, 先将间接左递归变换为直接左递归,然后依照上面的原理解决。
则同理对其他表达式做变换结果如下
ADD =(MUL | NUM)(+ (MUL | NUM) ) +
MUL = NUM(*NUM) +
NUM = 0-9
ADD中加号左右项相同, 我们把MUL与NUM合并,重新起个名字 factor , 则有
ADD = factor( ( + | - ) factor) *
factor = NUM( ( * | / ) NUM) *注意:最后面的 蓝色 星号表示:星号前面的项出现0~多次,至少0次,星号 前面的项为括号中的内容。
我们给NUM也重新起个名字 term, ADD 项 与 乘法表达式合并为表达式exp,则有:
exp = factor ( ( + | - ) factor ) *
factor = term ( ( * | / ) term) *
term = 0 - 9
到这里,就可以开始编写代码了,下面用代码来实现上述范式逻辑,
term 表示为0~9的字符串,则有代码:
static int term(byte[] data, int offset, int len){
int pos = offset;
for (; pos < len; pos ++){
if (!(data[pos] >= '0' && data[pos] <= '9')){
break;
}
}
if (pos == offset){
return -1;
}
return pos - offset;
}
factor 表示为 term + 0~多次的 ( 乘号或者除号 + term) ,则有代码:
static int factor(byte[] data, int offset, int len){
int pos = offset;
int nt = term(data, pos, len);
while (nt > 0){
pos += nt;
if (pos >= len){
break;
}
if (data[pos] == '*' || data[pos] == '/'){
nt = term(data, pos + 1, len);
}else{
break;
}
}
if (pos == offset){
return -1;
}
return pos - offset;
}
exp 表示为 factor + 0~多次的 ( 加号或者减号 + factor),则有代码:
static int exp(byte[] data, int offset, int len){
int pos = offset;
int nt = factor(data, pos, len);
while (nt > 0){
pos += nt;
if (pos >= len){
break;
}
if (data[pos] == '+' || data[pos] == '-'){
nt = factor(data, pos + 1, len);
}else{
break;
}
}
if (pos == offset){
return -1;
}
return pos - offset;
}
编写代码
三个方法的返回值均为处理的长度,返回-1表示处理失败,下面是能够运行的完整 xlang 代码:
//xlang Source, Name:Lexer.xcsm
//Date: Fri Sep 00:06:28 2019
package System{
public class out{
public static int println(String text){
return _system_.consoleWrite(text + "\n");
}
public static int print(String text){
return _system_.consoleWrite(text);
}
};
};
class Lexer{
/**
exp=factor((+|-)factor)*
factor=term((*|/)term)*
term=0-9
*/
/*** 用于接收每一步的结果 */
public static class Result{
public int value;
/*** 合并计算结果*/
public void patch(Result ctx, char v){
String resstr = (String.format("%d %c %d",value, v, ctx.value));
switch(v){
case '+':
value = value + ctx.value;
break;
case '-':
value = value - ctx.value;
break;
case '*':
value = value * ctx.value;
break;
case '/':
value = value / ctx.value;
break;
}
/** 打印计算过程到输出窗口 **/
_system_.output(resstr + " = " + value);
}
};
/** term=0-9 */
static int term(byte[] data, int offset, int len, Result ctx){
int pos = offset;
for (; pos < len; pos ++){
if (!(data[pos] >= '0' && data[pos] <= '9')){
break;
}
}
if (pos == offset){
return -1;
}
ctx.value = new String(data, offset, pos - offset).parseInt();
return pos - offset;
}
/** factor=term((*|/)term)* **/
static int factor(byte[] data, int offset, int len, Result ctx){
Result res = new Result(),
res1 = new Result();
int pos = offset;
int nt = term(data, pos, len, res);
while (nt > 0){
pos += nt;
if (pos >= len){
break;
}
if (data[pos] == '*' || data[pos] == '/'){
nt = term(data, pos + 1, len, res1);
if (nt > 0){
nt += 1;
res.patch(res1, data[pos]);
}
}else{
break;
}
}
if (pos == offset){
return -1;
}
ctx.value = res.value;
return pos - offset;
}
/** exp=factor((+|-)factor)* **/
static int exp(byte[] data, int offset, int len, Result ctx){
Result res = new Result(),
res1 = new Result();
int pos = offset;
int nt = factor(data, pos, len, res);
while (nt > 0){
pos += nt;
if (pos >= len){
break;
}
if (data[pos] == '+' || data[pos] == '-'){
nt = factor(data, pos + 1, len, res1);
if (nt > 0){
nt += 1;
res.patch(res1, data[pos]);
}
}else{
break;
}
}
if (pos == offset){
return -1;
}
ctx.value = res.value;
return pos - offset;
}
/** 做解析运算 **/
public static bool parse(String text, Result ctx){
byte [] data = text.getBytes();
return data.length == exp(data, 0, data.length, ctx);
}
};
int main(String [] args){
// 调用测试:
/** 用于接受结果**/
Lexer.Result res = new Lexer.Result();
/** 构造表达式字符串 */
String expression = "1+2+3+4*5+6*7+8";
/** 解析运算 */
if (false == Lexer.parse(expression,res)){
/** 解析错误 抛出异常 **/
throw new IllegalArgumentException("not a valid expression");
}else{
/** 在调试器的输出窗口中打印运算结果 **/
System.out.println(expression + " = " + res.value);
}
return 0;
}
运行测试
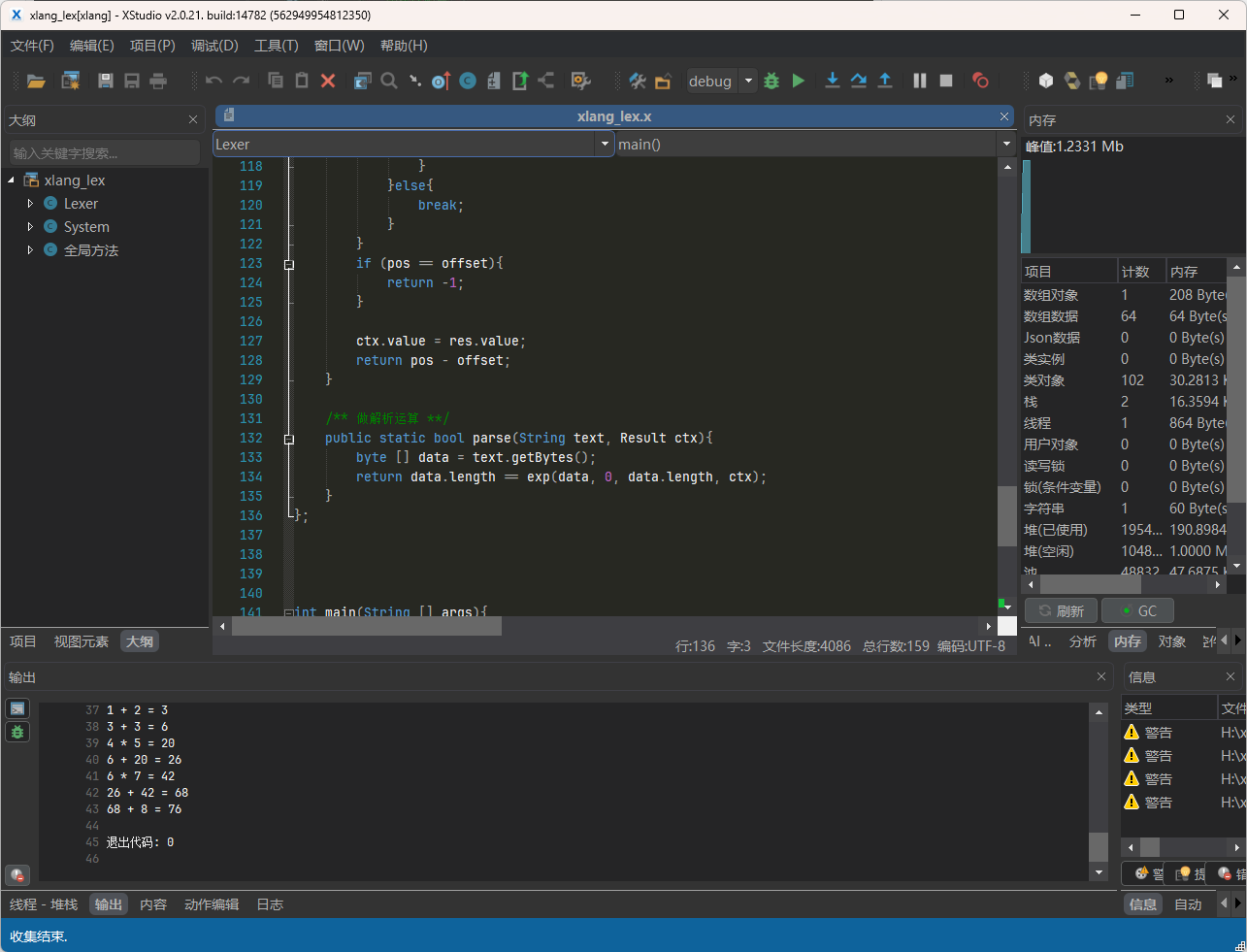
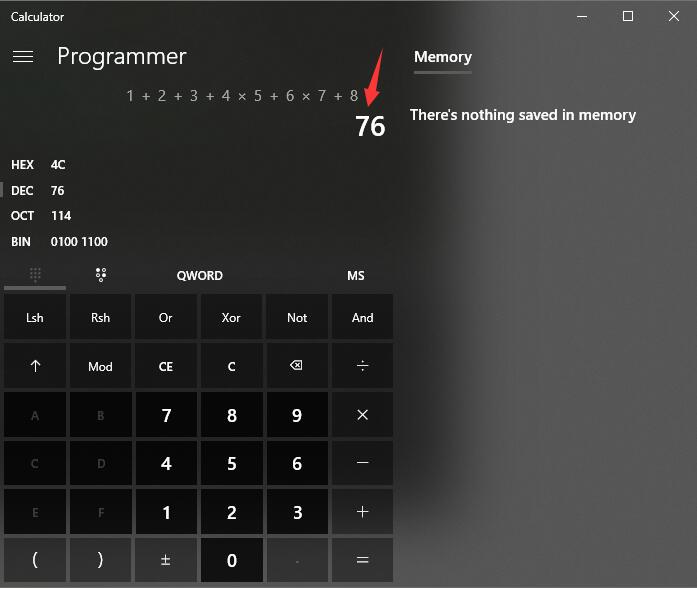
可以看见在输出窗口中已经打印出了结果,用windows的计算器来验证一下:
上一篇:使用AStyle对xlang源码格式化下一篇:用XStudio写一个HelloWorld

